车牌识别是智能交通系统的一个重要研究课题,存在巨大的市场需求。车牌识别系统分车辆图像的获取、车牌的定位与字符分割、车牌字符识别3大部分。对于车牌字符识别,目前最常用的方法是基于模板匹配的方法和基于神经网络的方法两大类。前者多利用了字符的轮廓、网格、投影等统计特征,相似字符区分能力差,且因特征数据维数过大会导致识别速度慢;而后者则存在网络输入数据的选择和网络结构设计等问题。
目前,普遍采用3类方法来提高字符的识别性能:第1类是寻找更好的分类识别算法;第2类是将几种分类器结合起来,相互补充,根据不同方面的特征分类,如文献;第3类是抽取具有更强描述能力的特征,结合其它辅助特征来进行分类,如文献。
本文采用支持向量机(SVM,support vector machine)的方法解决车牌字符识别问题,属于第1类方法。SVM可以自动寻找对分类有较好区分能力的支持向量,由此构成的分类器可以最大化类间间隔,达到正确区分类别的目的;在解决有限样本、非线性及高维模式识别问题中表现出了许多特有的优越性能,且具有适应性强和效率高的特点。
2 支持向量机简介
支持向量机(SVM)是Vapnik及其研究小组提出的针对二类别的分类问题而提出的一种分类技术,是一种新的非常有发展前景的分类技术。支持向量机的基本思想是在样本空间或特征空间,构造出最优超平面使超平面与不同类样本集之间的距离最大,从而达到最大的泛化能力,其算法的详细叙述可参考文献。
支持向量机方法根据Vapnik的结构风险最小化原则,尽量提高学习机的泛化能力,使有限少量训练样本得到的决策规则对独立的测试集仍能得到小的误差。这样只需有限的少量样本参与训练,就可以保证训练产生的分类器具有很小的误差。而车牌字符识别时,相对于预测的样本,只能有有限的少量样本参与训练,支持向量机的方法可以使训练产生的分类器在识别车牌字符时只有小的误差,并且大幅减少训练的时间。
对于数据分类问题,通用的神经网络方法的机理可以简单地描述为:系统随机产生一个超平面并移动它,直到训练集中属于不同类别的点正好位于平面的不同侧面。这种处理机制决定了神经网络方法最终获得的分割平面并不是一个最优超平面,只是一个局部的次优超平面。而SVM将最优超平面的求解问题转换为一个不等式约束下的二次函数寻优问题,这是一个凸二次优化问题,存在唯一解,能保证找到的极值解就是全局最优解。
SVM通过一个非线性函数将输入数据映射到具有高维甚至为无穷维的特征空间,并在这个高维特征空间进行线性分类,构造最优分类超平面,但在求解最优化问题和计算判别函数时并不需要显式计算该非线性函数,而只需计算核函数,从而避免特征空间维数灾难问题。
车牌字符识别问题中每个样本为一个字符图像,每个字符图像由许多像素组成,具有高维的特点。SVM通过核函数的计算,避免了神经网络解决样本空间的高维问题带来的网络结构设计问题,使训练模型与输入数据的维数无关;并且每个字符的整幅图像作为一个样本输入,不需要进行特征提取,节省了识别时间。
3 车牌字符分类器的构造
我国标准车牌格式是:X1X2.X3X4X5X6X7,其中X1是各省、直辖市和自治区的简称,X2是英文字母,X3X4是英文字母或阿拉伯数字,X5X6X7是阿拉伯数字,并且对于不同的Xl,X2的取值范围是不一样的。X2和X3之间有一小圆点。
针对车牌字符的排列特征,为了提高车牌整体的识别率,可以设计4个分类器来进行车牌字符的识别,即汉字分类器、数字分类器、英文字母分类器、数字+字母分类器。根据车牌中字符的序号,选择对应的分类器进行识别,然后将识别结果按字符序号进行组合,就得到了整个车牌的识别结果。4个分类器如图l所示。
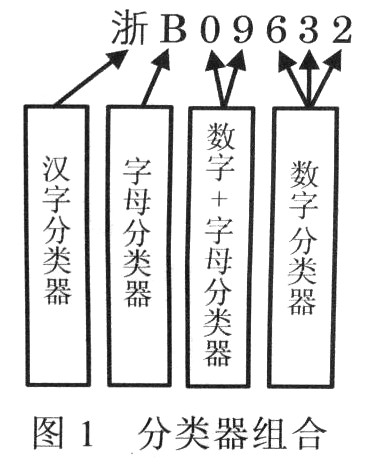
字符集中汉字有50多个,其中31个为各省、直辖市和自治区的简称;英文字母全部为大写字母,不含字母“I”,字母“o”归为数字“0”,故英文字母集由24个大写字母组成;数字为0~9的阿拉伯数字。
支持向量机是针对二类别的分类而提出的,但车牌字符识别是多类别的分类问题,需要将二类别分类方法扩展到多类别分类,本文采用了一一区分法实现。一一区分法(one—against—one method)是分别选取2个不同类别构成一个SVM子分类器,这样对于k类问题,共有k(k一1)/2个SVM子分类器。在构造类别i和类别j的SVM子分类器时,在样本数据集中选取属于类别i和类别j的样本数据作为训练样本数据,并将属于类别i的数据标记为正,将属于类别j的数据标记为负。测试时,将测试数据对k(k一1)/2个SVM子分类器分别进行测试,并累计各类别的得分,选择得分最高者所对应的类别为测试数据的类别。
4 最佳参数模型的选择
本文从某一实际卡口系统采集到的768×576像素的汽车牌照图片进行车牌定位和字符分割后,将分割的每个车牌字符进行二值化操作,字符笔划对应的像素置为l,背景像素置为0,再将每个字符归一化到13x24像素,并根据每个字符在车牌中的位置,编上序号l~7。
本文所选汽车牌照图片共计132张,包括晚上、逆光、字符磨损厉害、牌照倾斜和牌照旁挂其它牌子等情况;有129张图片可以实现车牌正确定位,车牌定位率为97.73%;120张图片可以实现所有字符正确分割,字符分割完全正确率为93.02%。
本文将每个字符作为一个样本,每个样本维数为312(13x24),根据其序号分成4类样本。每类样本分成两部分,60%的样本训练产生模型,另40%用于测试,核函数采用径向基函数K(xi,x)=exp(-||x-xi||2/σ2),分别训练生成4类分类器,从中选择最优参数模型组成4类最佳分类器,用来进行车牌字符的整体识别。
为了求解最佳的分类器参数(C,σ2),本文选择双线性法来求解最佳参数,对每类分类器模型采用以下步骤:
第一步:根据识别正确率确定最佳参数C。首先假设C=10,取σ2=10-1,100,101,102,103,得到最高的识别正确率对应的σ2,然后固定σ2,改变C的值,得到这时最高的识别正确率对应的C值,作为最佳参数C。
4类分类器的最高识别正确率对应的(C,σ2)都为(10,100),确定最佳C=10。
第二步:确定最佳参数(C,σ2)。固定最佳参数C,取σ2=l,10,100,200,300,400,500,600,700,800,900,1000,取最高识别正确率对应的(C,σ2)为分类器模型的最佳参数。
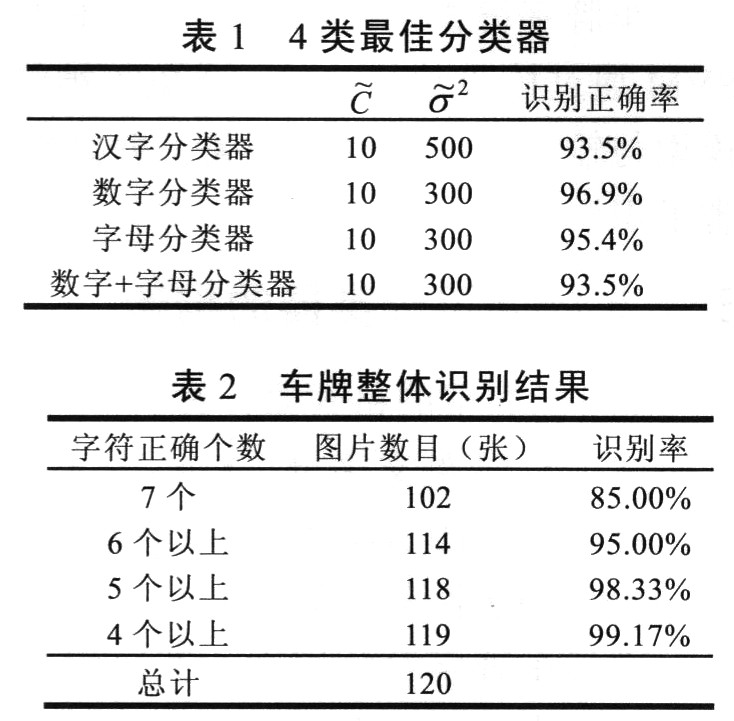
观察发现,4类分类器模型在σ2的值变为100以下时,对应的识别正确率都逐渐减小;σ2的值变为100以上时,对应的识别正确率先增大后减小,出现“峰值”,取“峰值”对应的模型参数为最佳参数。4类最佳分类器如下表1所示。
实验观察分析,分类器识别时具有一定的偏向性,即参与训练的某类样本数目多,预测样本识别为该类的概率就大,如训练样本中“浙”字较多,汉字分类器将预测样本识别为“浙”的可能性较大,而实际上预测样本中“浙”字数目较多,这样无形中就提高了识别正确率。
5 实验及结果
本文用以上4类最佳分类器的组合分类器对所有车牌字符进行整体识别,识别结果如表2所示。
在实际运用中,车牌字符正确数目在5个以上就能满足要求,本文与相关文献的车牌字符识别结果如表3所示。
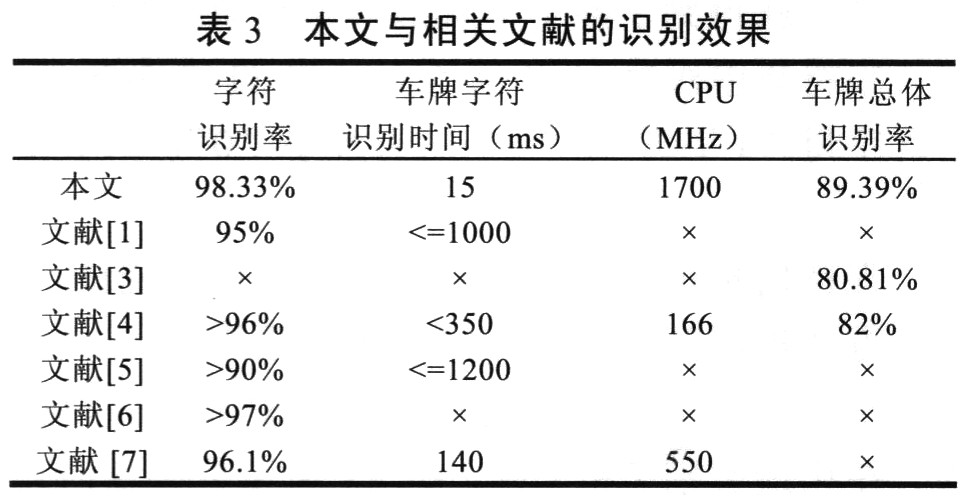
观察分析发现,影响识别效果的主要原因是相似字符的误识,如字符“D”和“0”、“B”和“8”等;还有汉字笔划多,二值化操作易造成笔划模糊,使汉字误识。
6 结论
本文将SVM的方法引入车牌字符识别中,在详细分析了车牌字符的排列特征的基础上,构造了用4个不同类别的SVM字符分类器;根据车牌字符的序号分别对应识别,再将识别结果组合,就得到了整幅车牌的号码。
SVM方法采用核函数解决了高维样本识别问题,不需要进行模型网络结构设计,并且不需进行特征提取,只需要有限的样本参入训练,节省了识别时间,这些都非常符合车牌字符识别的要求。本文采用一一区分法将SVM方法从二类别识别扩展到了多类别识别,并取得了满意的识别效果;但一一区分法需要保证训练样本的充分性,需要所有类别的样本都参加训练。
试验结果表明,本方法有较好的实用性,而进一步减少相似字符和汉字误识是本工作以后努力的方向,其关键是加强图像的预处理,改进字符分割方法和二值化方法,使字符笔划更清楚。