数字视频处理始终是目前多媒体设备应用中的热点问题。数字视频的标准繁多,并且在还持续地发展变化之中,因此,系统设计必须能够尽可能支持更广泛的视频格式。传统的选择是采用DSP进行软件编解码,但随着1080i/p的高清视频应用的迅速普及,其所要求的运算量也在急剧增长,基于软件的处理方式逐渐开始面临极大的挑战。而基于硬件加速器的方案优势则开始显现,这种方式可以大大减轻处理器负载,并满足移动设备苛刻的低功耗要求。目前,越来越多的系统方案开始采用基于全硬件视频处理引擎(VPU)的设计。
飞思卡尔i.MX53应用处理器提供了基于硬件加速器方式的典型结构,其内嵌的全硬件VPU支持从H.264、MPEG4、Divx到RV10在内的非常广泛的视频格式,可以涵盖绝大部分视频资源,并支持1080i/p高清解码和720p编码。此外,该处理器还可以同时进行多路视频解码和全双工多路视频编码处理,并且允许每一路视频采用不同的格式,从而可实现双显示器配置或视频电话会议应用等。
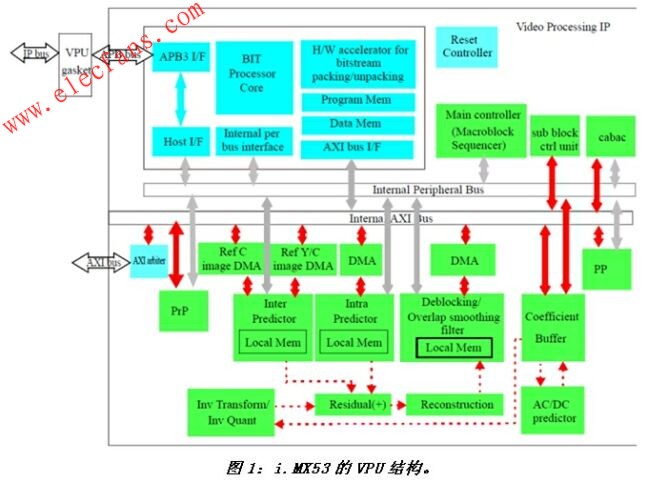
典型的硬件视频处理引擎结构
与通常意义上的全硬件VPU不同,该VPU的一个显著的优势在于可以在一定程度上提供可编程性,以及编解码流程的更新。原因就在于其内置有一个16位的小型可编程DSP,这个名为BIT的处理器可以通过执行不同的固件来灵活控制编解码的过程以及和CPU的接口 交互。
对于CPU来说,控制VPU所需要的运算量不超过1MIPS,如此之低的计算需求同样归功于BIT处理器。它的内部包含了专用硬件加速器来加速码流的处理,实现了包括帧率控制、FMO、ASO、视频编解码控制以及错误恢复等功能。VPU内大部分的子模块也经过高度优化,在编解码各种不同视频格式时可以充分复用,从而降低了门数和功耗。
MX53的VPU结构如图1所示,它通过标准的AXI/APB与ARM处理器相连,从而可以访问片内缓存来获得高性能。VPU主要包括两个组件,视频编解码处理IP和VPU总线转换器。前者是整个VPU的核心,主要由嵌入式BIT处理器,视频CODEC以及总线仲裁器组成;后者负责将AMBA APB3总线转换成VPU内部的IP Sky Blue总线。
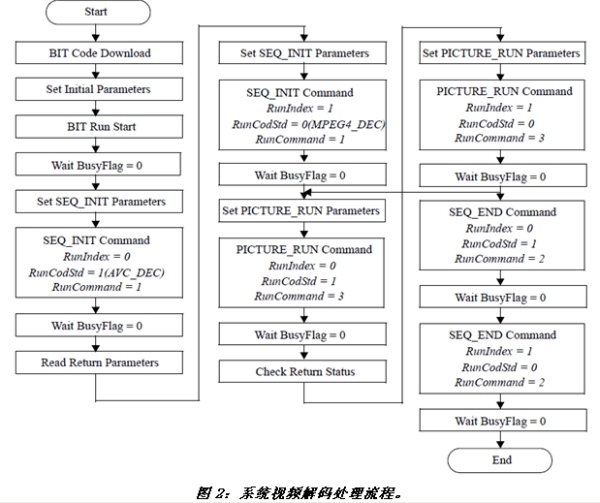
视频解码处理流程
得益于BIT处理器的高度完善的控制流程,从外部的CPU角度来看,VPU是高度自主控制的,CPU所需要做的仅仅是与VPU相关的进程管理工作。需要注意的是这里的进程并非指通常意义上的系统进程,而是VPU内部专用的进程。
VPU可以同时处理多达4路不同格式的视频,但处理流程都是相同的。都是从创建进程开始(系统负责创建和设置一个专用进程),再到运行进程(系统运行进程需要满足的时间点要求是解码器处于空闲状态并且码流已经在内存中就绪),最后退出进程。
如果有多个进程准备运行,每个进程将被分配一个唯一的进程索引号,该索引号基于创建的顺序进行分配。例如,当1路MPEG-4解码、1路H.264解码、1路MPGE-2解码和1路VC-1解码同时进行时,MPEG-4解码进程会被分配索引号0,而VC-1解码被分配为索引号3。
在多进程的环境下,进程的执行没有优先级之分。在创建了所有的进程之后,CPU将启动BIT处理器执行这些进程,BIT处理器同样是利用类似时间片分割的机制来调度一个进程。
我们跳出VPU,从整个系统的角度来看VPU的运作,下面以同时解码1路H.264码流和1路MPEG-4码流为例。
首先,初始化VPU,包括将BIT处理器所需的固件代码装入内存,设置初始化参数,如BIT处理器配置参数,工作缓冲区基地址、BIT代码地址以及码流缓冲区控制等等。
接着创建H.264码流和MPEG-4的解码进程,包括设置码流缓冲区的基地址和大小,帧缓冲区的基地址等。
然后每个进程交替执行。一个标记(Wait BusyFlag)指示是否一帧码流已经完成解码,完成解码后的码流将会被发往图像处理单元(IPU)进行后处理和显示。
最后,在解码结束后,释放相关的内存资源并销毁进程。
内存控制是使用VPU的关键问题
VPU对于外部内存有完全的访问权,它利用外部内存来加载和存储图像帧、码流以及BIT处理器的代码和数据。内存的使用量取决于视频格式本身和目标应用。例如,H.264解码使用的参考帧最多达16个,但H.263解码仅仅需要使用1个。此外,不同的格式在处理De-blocking或者叠加平滑滤波的时候也需要使用大小不同的临时内存。
基本上,VPU使用6种不同的存储区:帧缓冲区(用于储存一帧图像)、BIT处理器代码内存区、工作缓冲区(用于BIT处理器的中间数据以及供视频解码硬件使用)、码流缓冲区(用于加载码流)、参数缓冲区(用于BIT处理器命令执行以及返回数据)、搜索RAM(用于ME模块以减少外部内存的总线负荷)。
其中,码流缓冲区的处理很关键,对于每一个进程,系统必须分配一个独立的码流缓冲区。外部码流缓冲区将组成一个缓冲区环(ring buffer)。BIT处理器将在获得缓冲区环的起始地址后自动进行循环操作。
在解码处理中,CPU将码流写入到该缓冲区中,接着BIT处理器将读取该码流,如果二者配合不好,会导致码流的重写(overwriTIng)或者不足(underflow),一旦这种情况发生,解码就会失败。为了防止这种情况的发生,当前码流的缓冲区读/写指针必须在外部的CPU和VPU内部的BIT处理器之间交换。CPU操作的写指针和BIT操作的读指针必须都要写入内部寄存器,BIT处理器通过比较这两个指针来判断码流缓冲区是否有码流不足,如果是的话,则需要停止解码来阻止误读码流,直到CPU写入足够的码流数据并更新写指针。反过来,CPU也需要在对缓冲区环写入数据之前对读指针进行判断以确定不会发生码流重写。
在诸如1080i/p高清解码的应用下,VPU所要求的内存带宽很高,而现在的操作系统多为多任务操作系统,因此内存带宽不足的问题就很可能发生,这将导致播放不流畅甚至错误解码的情况发生。因此必须仔细规划系统带宽的使用。
本文小结
从上述的分析来看,对于i.MX53的VPU的使用是非常简单的,全硬件VPU对于编解码过程的高度封装实际上隐藏了这一过程的复杂性,使得从整体上来看,视频处理成为一件轻松的任务,这正是全硬件VPU的显著优势之一。目前,多媒体设备的市场竞争异常激烈,系统厂商的产品开发时间被压缩得非常短,就视频解决方案而言,应用处理器供应商必须保证其参考设计能够提供简洁易用的API,以及经过充分验证的可靠性和实时编解码性能,基于全硬件视频处理的系统设计无疑是一种极具市场吸引力的解决方案。