随着现代科技和计算机技术的不断发展,人们在与机器的信息交流中,需要一种更加方便、自然的交互方式,实现人机之间的语音交互,让机器听懂人话是人们梦寐以求的事情。语音识别技术的发展,使得这一理想得以实现,把语音识别技术与机器人控制技术相结合,正成为目前研究的热点,不但具有较好的理论意义,而且有较大的实用价值。
语音识别技术应用于机器人系统大多是针对特定的环境,设计出语音命令来进行控制的。只需要对几十个字或词的命令行进语音识别,便可使得原本需要手工操作的工作由语音轻松完成。本文针对现有机器人平台,设计一个非特定人的孤立词语音识别系统。
1 语音识别原理及JuliUS简介
1.1 基于HMM的语音识别原理
语音识别系统是一种模式识别系统,系统首先对语音信号进行分析,得到语音的特征参数,然后对这些参数进行处理,形成标准的模板。这个过程称为训练或学习。当有测试语音进入系统时,系统将对这些语音信号进行处理,然后进行参考模板的匹配,得出结果。此时便完成了语音识别的过程。
目前,HMM作为语音信号的一种统计模型,是语音识别技术的主流建模方法,正在语音处理各个领域中获得广泛的应用。现在许多商用语音软件,以及各种具有优良性能的语音识别系统,都是在此模型上开发的,已经形成了完整的理论框架。
基于HMM模式匹配算法的语音识别系统表现为:在训练阶段,采用HMM训练算法为每一个词条建立一个HMM模型。词条经过反复训练后,将得到的对应HMM模型加入HMM模型库中以数据的形式保存。在匹配阶段,也就是识别阶段,采用HMM匹配算法将输入的未知语音信号与训练阶段得到的模型库中的模型进行匹配,输出语音识别的结果。
1.2 JuliUS简介
Julius是日本京都大学和日本IPA(InformaTIon-tech-nology PromoTIon Agency)联合开发的一个实用高效双通道的大词汇连续语音识别引擎。目前已经能较好地应用于日语和汉语的大词汇量连续的语音识别系统。Julius由纯C语言开发,遵循GPL开源协议,能够运行在Lin-ux、Windows、Mac:OS X、Solaris以及其他Unix平台。Julius最新的版本采用模块化的设计思想,使得各功能模块可以通过参数配置。
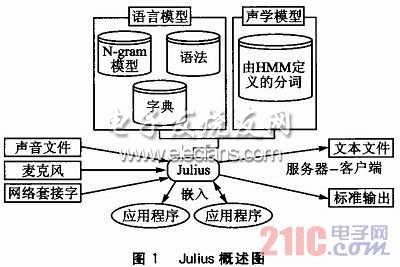
Julius的运行需要一个语言模型和一个声学模型。利用Julius,通过结合语言模型和声学模型,可以很方便地建立一个语音识别系统。语言模型包括一个词的发音字典和语法约束。Julius支持的语言模型包括:N-gram模型,以规则为基础的语法和针对孤立词识别的简单单词列表。声学模型必须是以分词为单位且由HMM定义的。
应用程序可以有两种方式与Julius交互:一种是基于套接字的服务器一客户端通信方式,另一种是基于函数库的嵌入方式。在这两种情况下,要识别过程结束,识别结果就被送入应用程序中,应用程序就能得到Julius引擎的现有状态和统计,并可以操作官。Julius概述如图1所示。