语音控制的基础就是语音识别技术,可以是特定人或者非特定人的。非特定人的应用更为广泛,对于用户而言不用训练,因此也更加方便。语音识别可以分为孤立词识别,连接词识别,以及大词汇量的连续词识别。对于智能机器人这类嵌入式应用而言,语音可以提供直接可靠的交互方式,语音识别技术的应用价值也就不言而喻。
1 语音识别概述
语音识别技术最早可以追溯到20世纪50年代,是试图使机器能“听懂”人类语音的技术。按照目前主流的研究方法,连续语音识别和孤立词语音识别采用的声学模型一般不同。孤立词语音识别一般采用DTW动态时间规整算法。连续语音识别一般采用HMM模型或者HMM与人工神经网络ANN相结合。
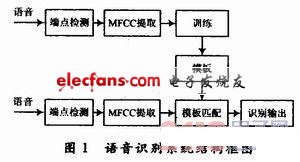
语音的能量来源于正常呼气时肺部呼出的稳定气流,喉部的声带既是阀门,又是振动部件。语音信号可以看作是一个时间序列,可以由隐马尔可夫模型(HMM)进行表征。语音信号经过数字化及滤噪处理之后,进行端点检测得到语音段。对语音段数据进行特征提取,语音信号就被转换成为了一个向量序列,作为观察值。在训练过程中,观察值用于估计HMM的参数。这些参数包括观察值的概率密度函数,及其对应的状态,状态转移概率等。当参数估计完成后,估计出的参数即用于识别。此时经过特征提取后的观察值作为测试数据进行识别,由此进行识别准确率的结果统计。训练及识别的结构框图如图1所示。
1. 1 端点检测
找到语音信号的起止点,从而减小语音信号处理过程中的计算量,是语音识别过程中一个基本而且重要的问题。端点作为语音分割的重要特征,其准确性在很大程度上影响系统识别的性能。
能零积定义:一帧时间范围内的信号能量与该段时间内信号过零率的乘积。
能零积门限检测算法可以在不丢失语音信息的情况下,对语音进行准确的端点检测,经过450个孤立词(数字“0~9”)测试准确率为98%以上,经该方法进行语音分割后的语音,在进入识别模块时识别正确率达95%。
当话者带有呼吸噪声,或周围环境出现持续时间较短能量较高的噪声,或者持续时间长而能量较弱的噪声时,能零积门限检测算法就不能对这些噪声进行滤除,进而被判作语音进入识别模块,导致误识。图2(a)所示为室内环境,正常情况下采集到的带有呼气噪声的数字“0~9”的语音信号,利用能零积门限检测算法得到的效果示意图。最前面一段信号为呼气噪声,之后为数字“0~9”的语音。
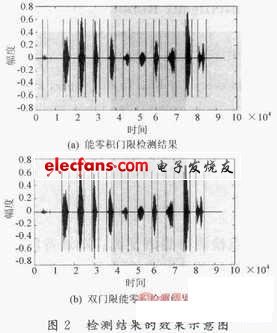
从图2(a)直观的显示出能零积算法在对付能量较弱,但持续时间长的噪音无能为力。由此引出了双门限能零积检测算法。
所谓的双门限能零积算法指的是进行两次门限判断。第一门限采用能零积,第二门限为单词能零积平均值。也即在前面介绍的能零积检测算法的基础上再进行一次能零积平均值的判决。其中,第二门限的设定依据取决于所有实验样本中呼气噪声的平均能零积及最小的语音单词能零积之间的一个常数。如图2(b)所示,即为图2(a)中所示的语音文件经过双门限能零积检测算法得到的检测结果。可以明显看到,最前一段信号,即呼气噪声已经被视为噪音滤除。