
机器深度学习是近年来在人工智能领域的重大突破之一,它在语音识别、自然语言处理、计算机视觉等领域都取得了不少成功。而对于当前大热的无人驾驶,深度学习可以带来哪些突破性应用?
由于车辆行驶环境复杂,当前感知技术在检测与识别精度方面无法满足无人驾驶发展需要,深度学习被证明在复杂环境感知方面有巨大优势。
近日,针对这一话题,北京航空航天大学交通学院副教授余贵珍,在2016年中国汽车工程学会暨展览会期间与广大汽车专业人士分享了他对于深度学习在无人驾驶环境感知中应用的体会和心得。余贵珍的研究方向主要是智能交通和无人驾驶的感知和控制。
视觉感知是无人驾驶的核心技术
无人驾驶一般包括四个等级或者五个等级,不管哪个等级都会包含环境感知、规划决策和执行控制等三个方面。其中环境感知方式主要有视觉感知、毫米波雷达感知和激光雷达感知,其中的视觉感知是无人驾驶感知的最主要的方式。
最近炒得比较热的特斯拉事件,一个是发生在美国,另外一个发生在中国,我想从技术的角度来谈谈。
在美国事件中,特斯拉车上的毫米波雷达因为安装的位置较低,无法检测卡车高的车厢,摄像头应该能检测到卡车了,我们知道特斯拉车辆是从远到近的过程中,所以从这个角度一般能够检测到卡车的。但是最后融合起来的时候可能出现了问题,没有检测到卡车。
在中国发生的事故,由于前车突然变道,故障车辆离特斯拉比较近,都在视觉感知和雷达的盲区,毫米波雷达由于前面角度的问题,无法扫描到近距离的侧向车。另外由于故障车的部分出现在摄像头中,视觉感知也没有办法检测到,发生了特斯拉这种刮蹭事故。
所以从以上事故可以看出,视觉感知仍然需要完善。
而中国的路况较为复杂,雨天、雾霾天以及下雪天。另外,像马车、吊车以及摩托车,还有摩托车拉猪、卡车拉树的现象在我们生活中经常遇到,这些场景对视觉是一个难题,提高这种复杂路况下的感知精度是无人驾驶研究的挑战。
深度学习能够满足复杂路况下视觉感知的高精度需求
深度学习被认为是一种有效的解决方案,深度学习是模拟人的大脑,是近10年来人工智能取得一个较大的突破。深度学习在视觉感知中近几年应取得了较大的进展,相对于传统的计算机视觉,深度学习在视觉感知精度方面有比较大的优势。
特别是2011年以后,有报导指出深度学习如果算法和样本量足够的话,其准确率可以达到99.9%以上,传统的视觉算法检测精度的极限在93%左右。而人的感知,也就是人能看到的准确率一般为95%,所以从这个方面看,深度学习在视觉感知方面是有优势的。
所谓深度学习,又名深度神经网络,相对于以前的神经网络来说是一种更多层和节点的神经网络机器学习算法,从这儿可以看出来,其实深度学习是一种机器学习,可以说是一种更智能的机器学习。深度学习主要类型一般包括5种类型,像CNN、RNN、LSTM、RBM和Autoencoder,其中我们主要的是用的CNN,CNN另外一个名字叫卷积神经网络。卷积神经网络已经被证明在图像处理中有很好的效果。
其中,自学特征是深度学习的最大优势。例如智能驾驶需要识别狗,在以前的算法中如果要识别狗,对狗的特征要用程序来详细描述,深度学习这个地方如果采集到足够的样本,然后放在深度学习中训练,训练出来后的系统就可以识别这个狗。传统的计算机的视觉算法需要手工提取特征,很多时候需要专家的知识,算法的鲁棒性设计非常困难,很难保证鲁棒性,我们做视觉感知的时候就遇到很多困难。另外如果要保证这个稳定需要大量的调试,非常耗时。
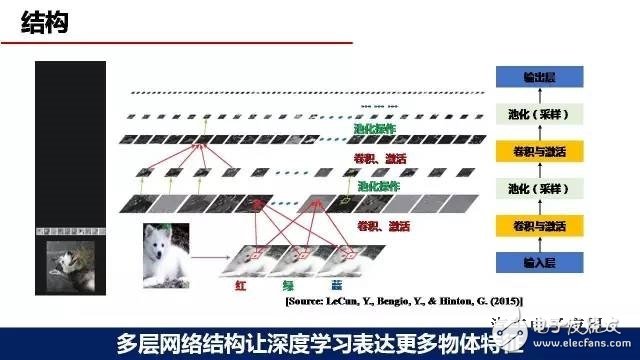
深度学习一般包括四种类型的神经网络层,输入层、卷积层、池化层、输出层。网络的结构可以10层甚至上百层,一般层数越多检测精度会更精准。并且随着网络层数和节点数的增加,可以表达更细、更多的识别物的特征,这样的话可以为检测精度的提高打下基础。
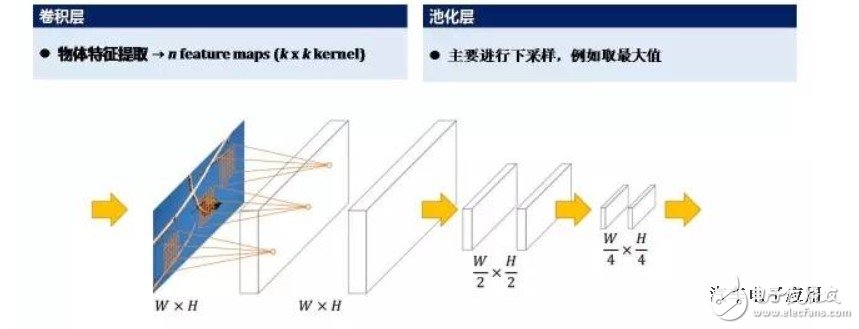
其中卷积层和池化层是深度学习的核心处理层。卷积层主要是用于负责物体特征的提取;池化层主要是负责采样。比如简单理解池化层,(就是一个数独里面取一个最大值),这就是池化层。卷积层与池化层是深度学习两个核心的层。
深度学习工作的原理,深度学习一般包括两个方面,一个是训练,一个是检测,训练一般主要是离线进行,就是把采集到的样本输入到训练的网络中。训练网络进行前向输出,然后利用标定信息进行反馈,最后训练出模型,这个模型导入到检测的网络中,检测网络就可以对输入的视频和图像进行检测和识别。通常情况下,样本的数量越多,识别的精度一般也会越高,所以这个样本的数量是影响深度学习精度重要的一个因素。
深度学习在无人驾驶感知上应用前景广阔
一般的环境感知方面用到的深度学习会多一些,主要是视觉与毫米波雷达方面。在驾驶策略里面也会用到机器学习,但是我们一般叫做增强学习,用于驾驶策略的研究。在环境感知方面,深度学习可以在视觉感知、激光雷达感知,还有驾驶员状态监测等方面,甚至在摄像头和毫米波雷达融合方面都具有优势。
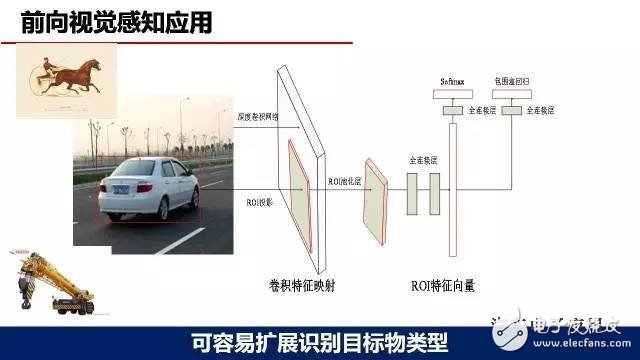
在环境感知方面,我们在这方面做的重要工作就是前向视觉感知应用。大家知道前向视觉感知是作为无人驾驶很重要的一部分,我们尝试深度学习在这方面一些应用。主要采用了单目摄像头的方案,选用的模型是Faster R-CNN,在GPU TITAN 平台上运行。目标检测物主要包括车道线、车辆、行人、交通标识和自行车,目前车辆的样本有3万左右,行人样本大概2万左右,其他的样本较少,大概1000—2000。从运行效果来看,识别精度、识别类型较以前开发的一些传统的视觉算法,我们觉得有比较大的改善。
深度学习的优势之一,容易扩展目标物体类型。
深度学习优势之二,能够提高部分遮挡物体的识别精度。

例如在图1中如果采用传统的视觉算法,人在车辆前面,一般的车辆检测比较困难。在图2中,可以看到深度学习的检测结果,红色车的前面已经有人和自行车,但是这个车辆仍然能够被检测到,采用深度学习能提高部分遮挡物体的识别精度。
深度学习优势之三,可以解决临车道车辆部分出现视频中的识别困难问题。

其中图1是采用传统的算法,右车道白色的车辆没有被检测出来。为什么没有被检测出来?我们知道一般的传统算法主要是对车辆后部的车子进行检测,对车辆侧向的检测并不好,离你最近的两个车道临近车辆其实对你也是一个危险物。如果能把左右车辆出现部分车辆能够检测出来,我觉得这个对视觉也是一个比较大的改善。前面讲的特斯拉事故,就是说一个车停在路旁,前面的车突然转道,刮蹭的事故中就是因为这个车辆离它太近,没有检测到故障车辆的原因。从图2中可以看到我们用深度学习检测的效果,右车道车辆只有部分在图像中,这个车辆仍然能够被检测出来。所以我们感觉利用深度学习可以解决临道车辆部分出现在视频中识别困难的问题。
深度学习优势之四,可以减少光线变化对物体识别精度的影响。
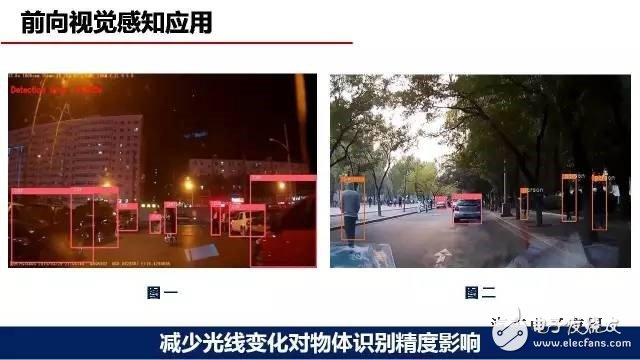
图1是晚上的识别效果,但是实际上我们整个训练样本中没有晚上的车辆和行人。我们最后是把训练之后的网络,检测晚上的视频,效果不错。图2中可以看出,右边树荫底下的几个人,其实如果用肉眼看很难分别出来有几个行人,但是使用深度学习,基本上能把行人都检测出来了。以上就是我们在深度学习中的一些体会,不一定正确,因为我们只是做了一些粗浅的研究。更细的问题,如果大家有什么好的建议,或者发现有一些更新的东西我们可以一起来分享。
小结:
1,深度学习在无人驾驶视觉感知方面,相对于传统的视觉算法,在精度、环境适应性和扩展性方面有一定的优势。前面看到的几个,都是我们做的一些实践的总结。
2,深度学习大家知道除了在视觉方面,在毫米波雷达、激光雷达甚至驾驶员识别方面,我们觉得也有广阔的应用前景。特别是驾驶员状态识别方面,我想提一下,因为最近特斯拉的一些事件都是驾驶员采用的无人驾驶状态,然后把手撒开方向盘,手没有在方向盘上。如果我们有一种摄像头可以检测到这个驾驶员状态的话,那么可以给驾驶员提醒,甚至说监督驾驶员是不是把手放在方向盘上,这样可以减少事故的发生。
3,我们这个PPT仅仅是探讨了深度学习在视频检测中的一些粗浅的应用,距离工程化应用方面仍然还有很多的技术困难需要克服。