在车联网时代来临的前夕,我们车上已经有 GPS、行车记录仪、蓝牙喇叭等设备,营造更便利的驾驶环境。不过,在上路前免不了的一连串手动输入或设定,却又不是那么方便了,更遑论开车到一半时要进行变更。即使是趁着等红灯的空档,只要还得伸手去屏幕上按来按去,就多少增加了行车风险。于是,为了驾驶人与乘客更舒适安全的的乘车体验,语音助理搭配人工智能将是不可或缺的环节。
然而,这样一来我们就得面对另一个难题,便是这些车用语音智能产品,如何能提供优异的语音辨识品质,提高辨识率,让机器准确接收我们的指令呢?想像一下,你载着满车朋友出游,在国道上高速行驶,大家快意谈笑,夹杂引擎运转与风噪声,可能还正好放着一首 Lana Del Rey 的《Burning Desire》,使你不自觉脚踩油门。这时车内环境噪音绝对高于 70dB(分贝),而且还夹杂不同频率的声音。因此,让产品侦测说话的人并接收正确指令,是相当令人头痛的问题。
环境噪音对语音通讯品质的影响
在语音辨识的流程中,可分为五道程序:包含语音输入及语音讯号处理、语音特征撷取、以声学模型(acousTIc model)进行语音单元辨识、以语言模型(language model)来组织语音单元、解码及输出等。
目前语音助理的市场上,Microsoft 耕耘最久,Apple、Google 相继而起,以完善智能手机体验为目标;近期火热的 Amazon Echo,其语音助理 Alexa 则一开始就以独立的声控家用平台为定位,建立自身生态系。以上这几家语音助理开发商,基本上已经掌握后面四道程序。不过,一旦来到车用领域,产品设备开发商则势必要在语音输入及语音讯号处理的程序上,投注更多心力。
车用语音智能产品在车内环境中,与使用者的距离不出 0.5~1 米之内。一般汽车引擎发动后且车窗紧闭的情况下,车内噪音约 60dB 左右。假设使用者发出约 89dB 的声音(即一般说话音量的平均值),此时嘴边的讯噪比为 29dB,足以维持良好的通讯品质。但你不会想要每次下指令还得把脸贴到汽车面板前,因此 0.5~1 米是产品接收语音讯号的合理距离。然而,当说话声音传到 0.5 米时会衰减至 65dB,此时讯噪比只剩 5dB;说话声音到 1 米时则只剩 60dB,与噪音的音量相当,更不用说上述提到高速行驶的环境下,噪音都比发出指令的人声还要大。
符合标准的车用通讯品质
当面临车联网逐渐完善、语音应用普及化,越来越多车厂要求内建 Android Auto、Apple Carplay 等智能助理,而这些都需要按照 ITU-T P.1110/P.1100 语音标准来设计,对代工组装或设计加工的车用电子系统厂来说,等于是踏入未知的领域,只能以现有产品不断侦错找出问题,相当耗费时间。因此像是贝尔声学这种第三方语音测试实验室,就会从麦克风模组、连接线材等部分测试,首先帮厂商判断选料是否正确。
贝尔声学曾针对一款旧的车用麦克风模组进行测试,该模组配两颗 ECM 电容式类比麦克风,一颗为全指向性,主要用来收环境音,作为背景噪音消除演算法的用途;另一颗为单指向性,收音方向指向驾驶,用来接收驾驶的语音讯号。依据 ITU-T P.1110 测试方式,得出了以下数据:
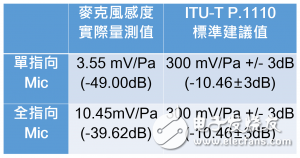
从结果可以看到,麦克风模组离标准建议值太远,感度差了约 30dB,因此讯号必须放大 30dB,才能满足标准建议值。然而,这意味着杂讯也会跟着放大,造成语音品质跟辨识率低落。代表这款麦克风一开始根本就不该出现在车用语音智能产品上。透过贝尔声学的协助,能让厂商快速找到症结点,避免进行过多无意义的测试。
由于车子所处的环境噪音会随着车速、路段、路况、空调、乘客及音响等各种因素不断改变,而背景降噪演算法不易解决时时变动且突发性的声音,所以车用语音智能产品可以着重在一些细节,帮助提升通讯品质。例如采用两颗以上的麦克风阵列,以进行较佳的背景降噪演算法;采用讯噪比较高的麦克风,最好是 SNR 58dB 以上。其次,把麦克风置于离驾驶嘴巴最近的位置,如方向盘附近;但同时又要尽量缩短麦克风线材至主机的距离,且加强线材隔绝性,以减少外来的杂讯。最后,则是加上回音消除(Echo cancellaTIon)、背景降噪(Background noise reducTIon)以及麦克风自动增益(Mic auto gain control)等三种功能,帮助提升语音辨识率。