随机智能手机的普及,在日常生活中,大多数人在做任何事情的时候,都会随身携带手机。如果开启手机中的传感器,当用户运动时,就可以采集大量的用户信息,根据这些信息,就可以判断当前用户的运动模式,如行走、上楼梯、下楼梯、坐、站立、躺下等等。基于这些运动模式,设计不同的场景,为健身类或运动类应用(APP)增加一些有趣功能。
在智能手机中,常见的位置信息传感器就是 加速度传感器(Accelerometer)和陀螺仪(Gyroscope)。
加速度传感器:用于测量手机移动速度的变化和位置的变化;
陀螺仪:用于测试手机移动方向的变化和旋转速度的变化;
传感器
本文主要根据手机的传感器数据,训练深度学习模型,用于预测用户的运动模式。
技术方案:
DL:DeepConvLSTM
Keras:2.1.5
TensorFlow:1.4.0
数据
本例的数据来源于UCI(即UC Irvine,加州大学欧文分校)。数据由年龄在19-48岁之间的30位志愿者,智能手机固定于他们的腰部,执行六项动作,即行走、上楼梯、下楼梯、坐、站立、躺下,同时在手机中存储传感器(加速度传感器和陀螺仪)的三维(XYZ轴)数据。传感器的频率被设置为50HZ(即每秒50次记录)。对于所输出传感器的维度数据,进行噪声过滤(Noise Filter),以2.56秒的固定窗口滑动,同时窗口之间包含50%的重叠,即每个窗口的数据维度是128(2.56*50)维,根据不同的运动类别,将数据进行标注。传感器含有三类:身体(Body)的加速度传感器、整体(Total)的加速度传感器、陀螺仪。
以下是根据数据绘制的运动曲线,站立(红色)、坐(绿色)、躺下(橙色)的振幅较小,而行走(蓝色)、上楼梯(紫色)、下楼梯(黑色)的振幅较大。
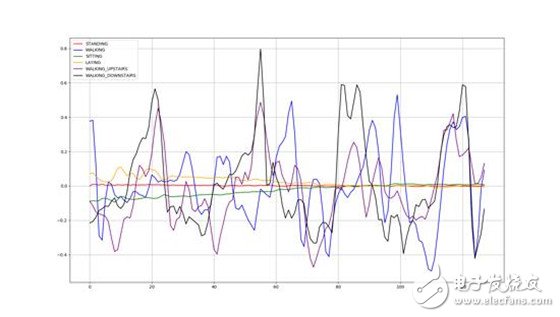
运动曲线
以下是在行走(Walking)中,三类传感器的三个轴,共9维数据的运动曲线:
传感器 - 行走
以下是在坐(Sitting)中的运动曲线:
传感器 - 坐
通过观察可知,不同运动模式的传感器数据曲线拥有一定的差异性,但是有些运动模式的差异性并不明显,如行走、上楼梯、下楼梯之间;相同运动模式的传感器数据曲线也各不相同。
在数据源中,70%的数据作为训练数据,30%的数据作为测试数据,生成训练数据的志愿者与生成测试数据的不同,以保证数据的严谨性,符合在实际应用中预测未知用户动作的准则。
UCI数据源
模型
模型是基于深度学习的DeepConvLSTM算法,算法融合了卷积(Convolution)和LSTM操作,既可以学习样本的空间属性,也可以学习时间属性。在卷积操作中,通过将信号与卷积核相乘,过滤波形信号,保留高层信息。在LSTM操作中,通过记忆或遗忘前序信息,发现信号之间的时序关系。
DeepConvLSTM算法的框架,如下:
DeepConvLSTM
将每类传感器(身体加速度、整体加速度、陀螺仪)的3个坐标轴(XYZ)数据,合并成一个数据矩阵,即 (128, 3)维,作为输入数据,每类传感器均创建1个DeepConvLSTM模型,共3个模型。通过3次卷积操作和3次LSTM操作,将数据抽象为128维的LSTM输出向量。
在CNN的卷积单元中,通过卷积(1x1卷积核)、BN、MaxPooling(2维chihua)、Dropout的组合操作,连续3组,最后一组执行Dropout。通过MaxPooling的降维操作( 2^3=8),将128维的数据转为为16维的高层特征。
CNN
在RNN的时序单元中,通过LSTM操作,隐含层神经元数设置为128个,连续三次,将16维的卷积特征转换为128维的时序特征,再执行Dropout操作。
LSTM
最后,将3个传感器的3个模型输出,合并(Merge)为一个输入,即 128*3=384,再执行Dropout、全连接(Dense)、BN等操作,最后使用Softmax激活函数,输出6个类别的概率。
Merged
选择概率较大的类别,作为最终预测的运动模式。
效果
在第48层中,即Concatenate层,将3个传感器的LSTM输出合并(Merge)成1个输入,不同类别的特征,效果也不同,如:
Merged Layer
训练参数:
epochs = 100batch_size = 256kernel_size = 3pool_size = 2dropout_rate = 0.15n_classes = 6
最终效果,在测试集中,准确率约为95%左右:
loss: 0.0131 - acc: 0.9962 - val_loss: 0.1332 - val_acc: 0.9535val_f1: 0.953794 — val_precision: 0.958533 — val_recall 0.949101
如果继续调整参数,还可以提升准确率。
通过深度学习算法训练的用户动作识别模型,可以应用于移动端进行场景检测,包含行走、上楼梯、下楼梯、坐、站立、躺下等六种动作。同时,95%的准确率已经满足大多数产品的需求。